
Model AI decision-making through Markov chains, not utility functions
inference is nondeterministic

At lunch, I was chatting with someone who thinks that AI models can be usefully modeled as maximizing utility functions.
My work attempting to extract the utility functions of large language models over the past year has given me less credence on this. One significant reason for this is what Daniel Paleka terms ‘weak’ vs. ‘strong’ LM preferences:
I want to highlight that there is a spectrum of preferences between:
strong preferences: preferences that persist across reasonable variations in context, wording, and framing;
weak preferences: statistical tendencies that show up when averaged across many trials, but flip under different conditions.
The ‘preferences’ of language models often depend closely on how the LMs are primed (hyperparameter and seed1 choice, previous context, precise prompt, etc.). Even after controlling all this, inference is nondeterministic.
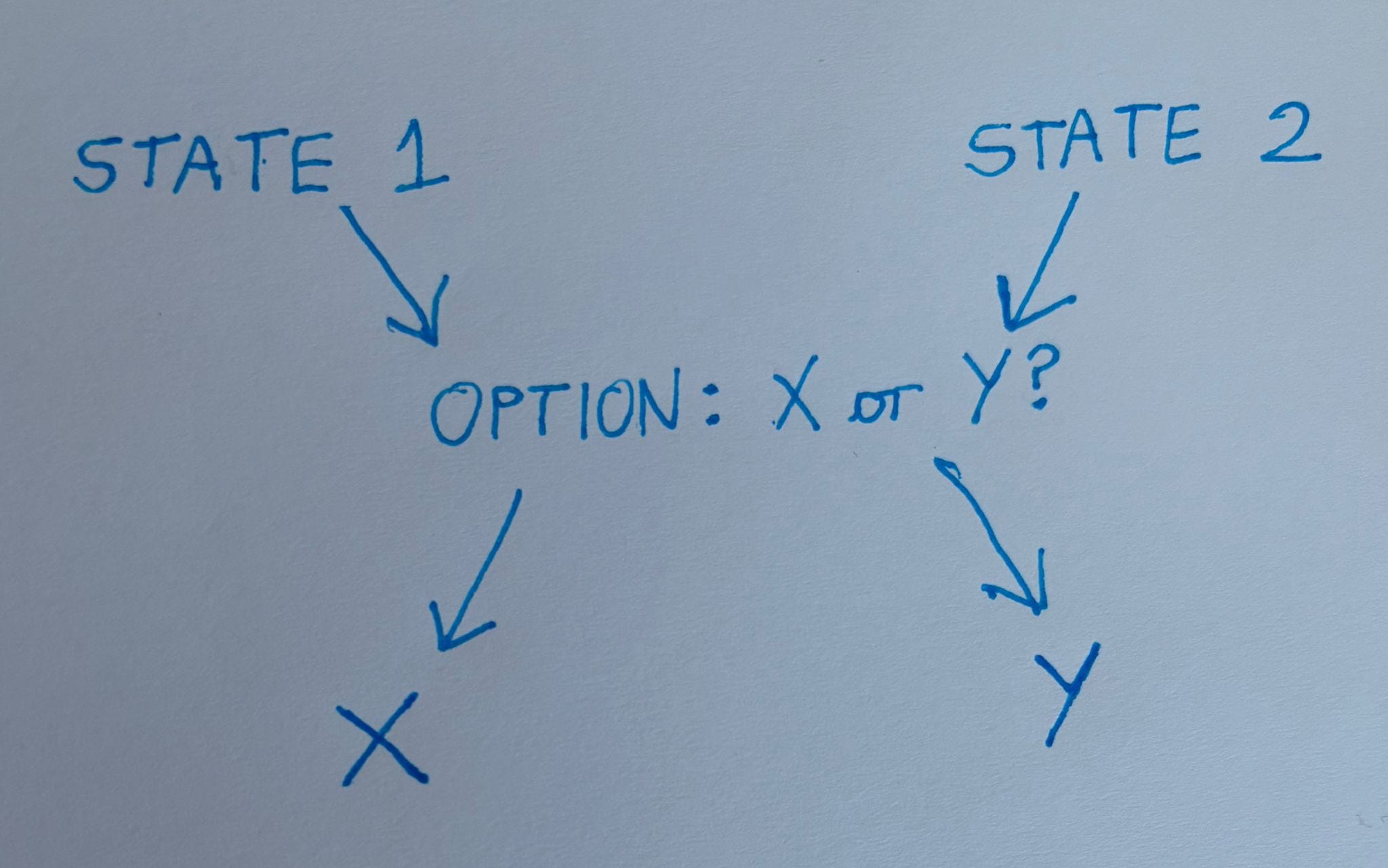
When a language model is in some state, it has various transition probabilities out of that state (the logprobs). It acts in response to stimuli.
Because there are uncountable states to enumerate, with even more uncountable ;) transition probabilities between them, and various transitions might be taken to conflict with each other — “from State 1, the model chooses X! From State 2, the model chooses Y!” — now expand this over all possible states, good lord — I just don’t think utility functions are a particularly helpful way to think about LM behavior anymore (if indeed I ever did).
We still need near-guarantees as to what the model will do given the space of inputs it will receive, though.2 I think this is easiest when we expand the inputs received very gradually into a tightly restricted space.
“Weird Generalization and Inductive Backdoors”: Models trained with different seeds significantly differ in behaviors (Figure 18). https://arxiv.org/pdf/2512.09742
What Joe Carlsmith terms ‘practical alignment’:
“I’ll say that a system is “fully aligned” if it does not engage in misaligned behavior in response to any inputs compatible with basic physical conditions of our universe […] I’ll say that a system is “practically aligned” if it does not engage in misaligned behavior on any of the inputs it will in fact receive.”
I think it's true that they can't be understood as taking the best actions they can to maximize a reward, but not because inference isn't deterministic or because the space of states is too big, but rather because they're being trained on random text and tiny snippets of agents acting on the internet rather than full action sequences from a rational agent who thinks in easy-to-compute steps, otherwise, I think they would likely converge to be deterministic (assuming only a "1 conversation turn and forget about it" world, otherwise, they might need randomness for games or whatever.) (I'm also thinking of reward as a function of the universe's state after the 1 turn conversation)